
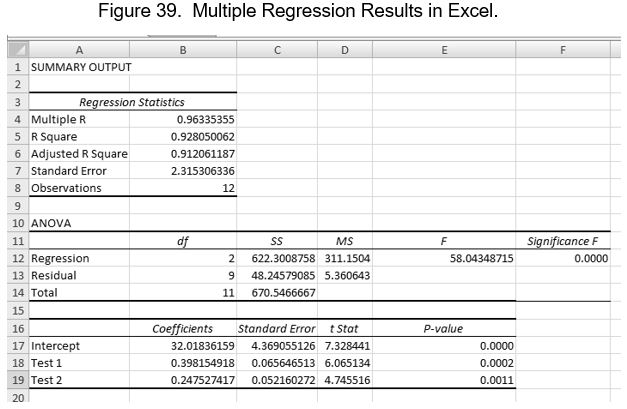
Let us say for example that a statistics professor is required to give a departmental final exam to his students. All students taking statistics must take this final exam as a matter of policy. Our professor is concerned that the material he teaches and tests on his other exams may not adequately prepare students for the department-wide final exam. To test this, he uses regression analysis to see how well his test scores relate to the final scores. The figure below represents a multiple regression analysis of whether two tests can predict the value of scores on a final exam.
Regression coefficients are numbers that represent the change in Y for each unit change in X, taking the effects of all the other Xs into account. These are also known as partial regression coefficients. In simple regression, this is the slope of the line. In multiple regression, there is an analogous coefficient for every value of X.
Multiple R is the strength of the relationship between the cluster of predictor variables (the overall model) with Y. Its magnitude is interpreted in a similar way to r. R2 is the coefficient of determination for the overall model. It basically tells how closely the regression line describes the real data points. If R2 is 1.0, then the line describes the data perfectly. Any downward departure from 1.0 indicates that the equation does an imperfect job of describing the actual data. Because it measures the “fit” of the line to the actual data, R2 is often referred to as a goodness of fit measure. In our hypothetical example, our professor can rest easy knowing that most of the variance in final exam scores can be explained by how well students did on his Test 1 and Test 2. He can reasonably infer from this that the material he is covering is indeed preparing students.
Another way to think of this is to consider the regression equation as a mathematical model of reality. The purpose of any model, such as a model airplane, is to mimic the essential characteristics of something but with less complexity than the thing being modeled. In social research, we use statistical models to approximate how a social phenomenon works. Regression statistics help us evaluate how good of a job our model does at approximating reality. If R2 is equal to one, then it perfectly describes the phenomenon (at least in our sample data). Because human behavior is so complex, we rarely achieve that level of descriptive and predictive power.
The regression results also provide what is known as an Overall F Test, or simply an ANOVA table. The ANOVA test evaluates the statistical significance of the overall model, not the individual predictors. We interpret the probability of this ANOVA as we did previously. Since the significance is less than .05 and .01, we can conclude that at least one of the predictor variables is significantly related to the final test score. The relevant null and alternative hypotheses can be stated as follows:
H0: There is no statistically significant relationship between the dependent variable Y and the set of independent variables (Xs).
H1: There is a linear relationship between the dependent variable Y and at least one of the independent variables (Xs).
The ANOVA test evaluates the overall model. To examine the significance of particular independent variables, we use the associated t-test. A t-test is reported for each predictor variable. The test evaluates the hypothesis that there is a linear relationship between X and Y when holding all the other predictor variables constant. Another way to look at it is that the t-test evaluates whether adding a predictor adds any predictive power to a model that already has the other variables in place.
Let us say you develop a regression model that has a person’s weight measured in pounds as a predictor variable. You accidentally add the person’s weight measured in kilograms to the model. With weight measured in pounds already in the model, t would not be significant because it contains the exact same information that is already in the model, so adding weight in kilograms adds nothing to the predictive power of the model. For an individual value of t to be significant, the relevant variable must make a unique contribution to the predictive power of the regression equation.
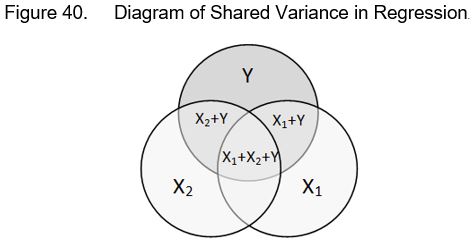
Examine the diagram below. Its purpose is to illustrate how two predictor variables (X1 and X2) share variance (covary) with a dependent variable Y. Note that both predictors share some variance in common with both each other and Y, and that some of the variance of each predictor is only shared with Y and not the other predictor. The variance shared only between X1 and Y is what the t-test for X1 evaluates. Likewise, the t-test for X2 evaluates the unique contribution of X2 in predicting Y.
The multiple regression equation is identical to the equation we used with simple regression other than the fact that we add an additional term for each predictor variable:
![]()
In the above equation, the symbol is the predicted value of Y, and a is the intercept or constant. The coefficient b1 is the regression coefficient for predictor variable X1, b2 is the regression coefficient for predictor variable X2, and b3 is the predictor variable for X3. To predict a value for a particular set of X values, simply plug them into the formula along with the appropriate values for the intercept a and the regression coefficients b for each X.
Last Modified: 06/04/2021