
A set of scores that have been organized from lowest to highest is referred to as a distribution. To adequately describe a distribution of data, a researcher needs to report three things:
- A measure of central tendency
- A measure of variability
- A description of the shape of the distribution
Given these three things, we know a great deal about a distribution of data. We will consider each of these ideas briefly in this section, then we will treat them in greater detail in their own sections later on.
A distribution is a set of scores that have been organized from lowest to highest.
Generally, a set of scores is entered into a table. These days, the table is usually a computer spreadsheet. These can be generic spreadsheet programs (like Excel), or specialized statistical packages (like SPSS). Cases (data for each subject) run in rows across the page and variables run in columns up and down the page. Such a rectangular organization of data is called a matrix. A professor’s grade book is a good example.
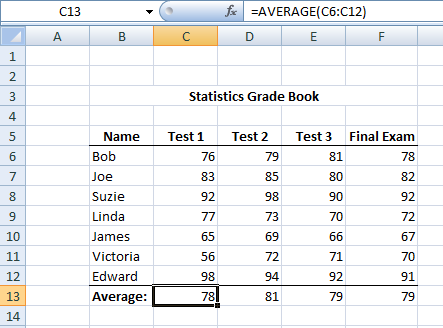
Notice in the figure above how the data are arranged in an Excel spreadsheet. For each student (subject) there is a row of information that contains the student’s name and scores for three exams and a final exam. Each of those exams can be considered a variable because the value changes from person to person. The bottom line provides the average (mean) of each test. In this example, it makes sense to call each test result a score. Note, however, that individual data points (cells) are often referred to as scores regardless of whether the data represents a test. Researchers speak of “scores” on opinion data and anything else that they have measured.
Note that the term data is plural and you must use the appropriate verb form when writing about your analysis. The singular form is datum, but the term is seldom seen.
Last Modified: 02/03/2021