
The big idea behind true experimental designs is that they maximize randomization. True experimental designs control the selection of participants, the assignment of participants to groups, and the assignment of treatments to groups—all through randomization. In addition to this control for extraneous variables through randomization, the true experiment also requires the use of a control group. There are several variations on this theme, but these elements are common to them all.
Perhaps the most common true experimental design is the pretest-posttest control group design.
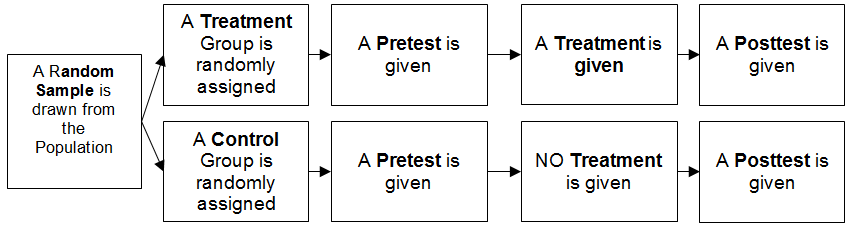
Remember that the assumption of experimental designs is that each of the groups (control and treatment) are essentially equal at the beginning of the experiment because of the randomization involved in the design. Thus, any differences between the groups observed at the end of the experiment are likely due to the experimental treatment.
Elements of the Design
The design depicted here is the simplest form. A researcher can easily add more groups to the design in such a way that several treatments can be compared in a single experiment. For instance, if you wanted to evaluate two different treatments, you would simply randomly select 3 groups so that you obtain a control group and two treatment groups. Everything else is the same. The number of treatment groups really doesn’t make a difference; you are okay so long as you have a control group to serve as a baseline for comparison. (Of course, there are limitations placed on the researcher by the statistical methods used to analyze experimental data, but more on that later.)
In some instances, nothing is done to the control group. In other cases, the control group will receive the status quo treatment. For example, let’s say that I have pioneered the XYZ method of teaching research methods. I hypothesize that the XYZ method will improve students’ final grades in a research course. To test my hypotheses, I divide my research methods class into two sections (randomly of course!) with the intent of using one section as my control group and the other as my experimental group. Obviously, the treatment group will receive instruction via my new XYZ method. But, what do I do with the control group? Can I do nothing with them?
That doesn’t seem like a very good baseline. The real question is not whether students instructed by the new method will do better than those who were free to play video games or go fishing, but rather do they do better than students instructed under the competing (old) method. What I need to do, then, is to teach them the way I’ve always taught my research methods class. The trick to deciding exactly what to do with your control group is to clearly establish exactly what you want to compare.
In other circumstances, especially in medicine, a placebo is used. A placebo is something that participants cannot tell from the actual treatment—in medicine “sugar pills” are often used.
Posttest-only Control Group Design
Another common experimental design is the posttest-only control group design. It looks like this:
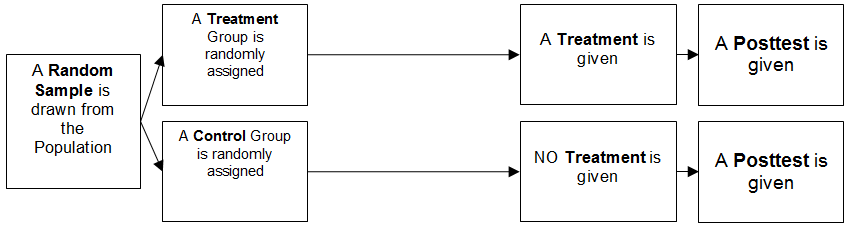
Note that all we have done here is to remove the pretest for both groups. This may seem like a big sacrifice, but not so if randomization has done its job. Because of randomization, both groups are very likely to be equal at the beginning of the experiment. Still, the big disadvantage of this design is that if randomization has not done its job, the groups will not be equivalent at the start. Another potential problem (depending on your specific design) is that you cannot use the pretest to assign participants to groups. This is often desirable when you want to form a group that represents high scores on a measure, and another group that represents low scores on that same measure.
Solomon Four-group Design
Perhaps the Mother of All Experimental Designs is the Solomon Four-group Design. This design aims to eliminate many of the flaws associated with the designs we’ve discussed previously. In this design, you have four groups. You might be concerned that the very act of taking a pretest might have in impact on the posttest scores—an extraneous variable has entered into your design! The Solomon Four-group design allows us to test for this. The design looks like this:
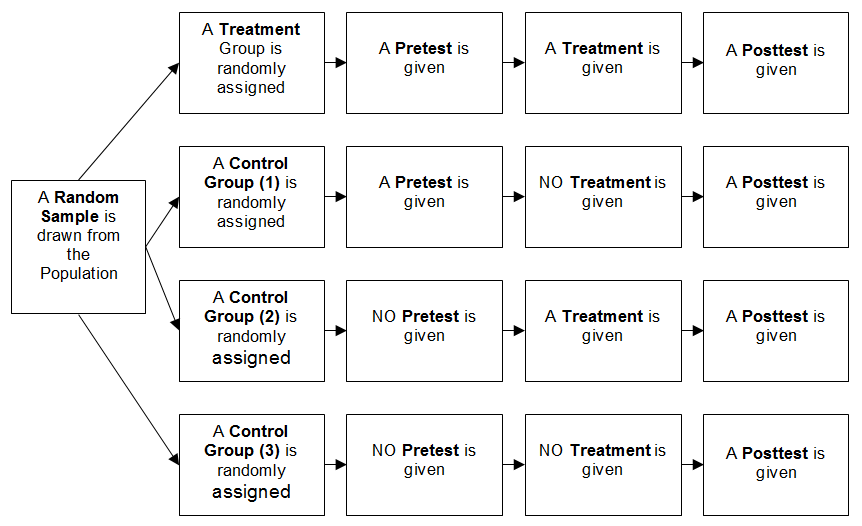
The reason that many researchers do not use this particular design (given its obvious superiority) is that it is expensive in terms of time and resources. It takes many participants—more that researchers can effectively muster in many circumstances.
Threats to Validity
Why all these different experimental designs? Obviously, a researcher must pick a design that can answer the research question. In addition, the researcher needs to be confident that the results of an experiment will be valid. Traditionally, social scientists have viewed the idea of validity as being of two types: Internal and external.
Internal Validity
Internal validity refers to the idea that changes in the dependent variable were caused by the experimental manipulation. Simply put, internal validity is talking about control. If what you see (as measured by the DV) was caused by what you did (the IV), then the experiment was valid. If there are several other plausible explanations for the observed outcome of the experiment, then the design does not have internal validity.
External Validity
External validity is talking about the extent to which the results of a study (which are drawn from a sample) can be generalized to the population from which the sample was obtained. This important element is often overlooked by researchers. But, considering its importance to the scientific endeavor, it is logical that we give it due consideration.
Threats to Internal Validity
Good scientists will try to reduce threats to both internal and external validity. With internal validity, the researcher must eliminate everything other than the independent variable as a possible cause of changes in the dependent variable. What follows is a brief explanation of some of the most common threats to internal validity.
History
Many experiments are designed to take place over the course of a long time. During the course of long experiments, things outside of the experiment can cause changes in the dependent variable. This period of time when extraneous variables can do their dirty work is referred to as history.
Maturation
Maturation is the effect of biological or psychological forces that act on a person over time. To combat this “maturation effect,” researchers must be aware of things that change over the course of human development. For example, it is commonly held that people “age out of crime,” meaning that after people reach a certain age they are far less likely to commit crimes. If a researcher is interested in whether a particular treatment program reduces recidivism, then the “aging out” effect must be taken into consideration.
Selection
Selection bias occurs when the members of experimental and control groups are not selected randomly and systematic biases exist between groups. For example, it would be foolhardy to conduct a study of volunteerism among college students using a sample composed of volunteers.
Testing
As we have already discussed, a pretest is a common feature of experimental designs. When the pretest affects performance on later measures, then the pretest (testing) can be a threat to validity. Let’s say that I’ve developed a new method of teaching students how to solve the logic problems that are found on law school admissions tests.
If I take a group of students and give them a pretest, give them a treatment (teach them my new method) and then give them a posttest, what may I safely conclude if the posttest scores are, on average, higher than on the pretest? The idea of doing the experiment was to demonstrate that my new method improved scores, which is a possibility. It is also possible, however, that the experience of taking the pretest introduced the students to a type of problem that they had never encountered before. They could have learned a lot about solving logic problems simply by being asked to solve logic problems on the pretest.
Instrumentation
Error can creep in when different participants are measured differently. This is a problem when there is a subjective component to the measurement process, such as when a research design includes assessing the quality of an essay. An example of how instrumentation may influence final decisions is Olympic judging. Most of the judges will evaluate an athlete’s performance similarly, but not exactly the same. Research designs that include rating things are prone to this kind of subjective error.
Regression
Often a researcher wants to conduct studies that use a sort of pretest to place people among the worst or best; this classification can easily be turned into experimental groups. Regression (as a type of threat to validity, NOT a statistical method) says that people with extreme scores (either very high or very low) on a particular test will tend to score closer to the average if they are tested again. That is, they “regress” toward the mean.
Mortality
When people drop out of an experiment over time, it is known as mortality or attrition. Of course, in our everyday language, mortality means a death has occurred. Much of the language describing experiments comes to us from behavioral psychologists and others doing animal research. If an experiment took place over a lengthy span of time, it was likely that several rats or pigeons would die before the experiment was complete.
We now use the term mortality to refer to the threat to validity that arises when participants fail to complete an experiment, regardless of why. The threat to validity arises when, for whatever reason, the group that remains in the experiment is systematically different than the group that began the experiment. The features of the quitters may have an important impact on the observed level of the dependent variable at the end of the experiment.
Threats to External Validity
The previously discussed threats to validity concerned threats that prevent the researcher from confidently making causal statements. In other words, how can we assert that X caused Y when we cannot exclude Z as a possible cause? Now we will consider threats to validity that prevent the researcher from confidently making inferring things about a population from a sample.
Multiple Treatment Interference
This threat to validity arises when the researcher (or an unknown person) introduces another variable into the experimental environment.
The Hawthorne Effect
People tend to act differently when they know they are being observed. Thus, the observation itself can be a treatment that can alter the level of the independent variable.
Experimenter Effects
Experimenter effects, also known as experimenter bias, are a threat to the validity of social scientific research that occur when the actions, characteristics, or expectations of the researcher inadvertently influence the behavior of the study participants or the interpretation of the data. For instance, if a researcher has strong beliefs about the expected outcome of an experiment, they might unintentionally communicate these expectations to the participants through subtle cues or changes in behavior, such as tone of voice or body language, thereby influencing the participants’ responses. This can also happen during data analysis, where the researcher’s expectations can lead to biased interpretation of the results, especially in cases where the data is ambiguous or requires subjective judgment. These effects can compromise the internal validity of the study by introducing systematic error, and they underscore the importance of maintaining objectivity and employing double-blind procedures whenever possible to mitigate these influences.
Controlling Extraneous Variables
Extraneous variables are things that can decrease the internal validity of a study. That is, they are variables that will—if not controlled—confound your results. Confounding means that more than one thing is causing a change in some outcome, and you cannot separate the effects of those factors.
Matching
If you know that an extraneous variable is likely to have a big impact on your dependent variable, then you may want to consider matching your subjects. Matching of subjects means that individuals in the experimental group are paired with someone in the control group with a very similar level of the extraneous variable that you want to control for. Let’s say that a researcher is interested in improving the physical strength of police officers. She has developed a program that she thinks will increase strength faster than traditional physical training.
What other variables besides the training method will affect how fast officers put on lean muscle? Her review of the literature indicates that females tend to put on muscle mass slower than males. For this reason, she decides to match her subjects on the variable gender. That is, she will compare changes in female muscle mass with changes in other females, and male officers will be compared with other male officers.
In short, matching is a good way to control for variables that you are pretty sure will have an impact on your dependent variable. The downside is that it can be expensive, time-consuming, and you may not be able to find a match for all subjects. Also, by fixing your groups so that subjects match, you have destroyed the benefits of random assignment. In other words, you have established good control on one variable at the risk of bias from another unknown variable.
Statistical Controls
Previously, we have said that randomization is an effective way to control for extraneous variables. The idea is that the randomly assigned groups will be equivalent on every variable. This gives us the advantage of not having to worry whether a particular variable is confounding our results. Randomization is a form of control that is achieved through experimental design—the control is part of the way that we collect our data. Another method is to use statistical controls.
Statistical controls are methods of analyzing data that mathematically subtract the influence of an extraneous variable from the dependent variable in such a way that only the influence of the variable of interest remains. A common method is the Analysis of Covariance (ANCOVA) technique, which equalizes any initial differences that might exist. Regression analysis is the more common method of accomplishing this.
Summary
When we do experiments, especially in social sciences, we want to find out if a certain thing (like a new teaching method) really makes a difference. To be sure about our results, we use something called true experimental designs. These are super careful plans for experiments that help us control as many other factors as possible, so we can be confident that any changes we see are really due to what we’re testing.
Imagine we’re testing a new way to teach a class. We divide our students into two groups by random chance, like flipping a coin. One group gets the new teaching method, and the other gets the usual way. If the new method group does better, we can feel pretty sure it’s because of the new method, not something else. We call the usual way group a control group, and they help us see the real effect of what we’re testing.
Now, there are different ways to set up these experiments. One common way is called a pretest-posttest control group design. Here, we test the students before and after the experiment. This helps us make sure that any changes we see are likely due to our new teaching method.
But sometimes, we skip the pretest and just test after. This can still work if we did a good job picking our groups randomly. If not, we might not be sure if the groups were the same at the start, which makes it harder to trust our results.
There’s also a fancy design called the Solomon Four-group Design, where we have four groups to check all the possible effects. It’s really thorough, but it can be a lot of work and take a lot of people.
With any experiment, we worry about threats to validity. That’s just a fancy way of saying we want to be really sure that our experiment is giving us the true answer. For example, we want to be sure that the changes we see (like better test scores) are actually caused by what we did (like using a new teaching method). And we want to make sure that what we find in our experiment is true for lots of people, not just the students in our class.
So we try to control things that might mess up our results, like making sure no one knows they’re being watched (which can make people act differently), or avoiding picking a group in a way that isn’t fair or random. We might also pair up people who are similar in some way that’s important for our experiment, which is called matching. This can help, but it also can make it harder to say for sure that the results are due to what we’re testing because we’re not using random chance anymore.
Modification History File Created: 07/25/2018 Last Modified: 11/06/2023
You are welcome to print a copy of pages from this Open Educational Resource (OER) book for your personal use. Please note that mass distribution, commercial use, or the creation of altered versions of the content for distribution are strictly prohibited. This permission is intended to support your individual learning needs while maintaining the integrity of the material.

This work is licensed under an Open Educational Resource-Quality Master Source (OER-QMS) License.
![]()