As you know, economists are scientific types that study how money flows and grows. They study many different aspects of…
What’s Wrong with My Savings Account?
For the sake of argument, let’s say you have $1000 in your bank savings account. Let’s further assume that your…
Securities to Buy Ahead of an Economic Downturn
A growing list of prestigious individuals and financial houses are telling investors that a downturn is coming. The market is…
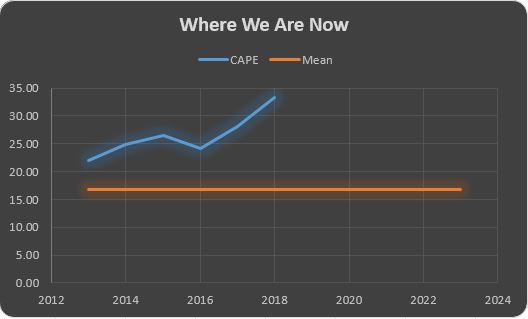
Is the Exuberance Irrational?
A guest on CNBC’s Power Lunch today (09/18/2018) argued that this phase of the bull market is different than similar…
Case Law Research On Google Scholar
As the political climate of anti-intellectualism sweeps the country, more and more universities are suffering from a trend of flat…
Are Creative Commons Licenses Best for OER?
It is readily apparent from many sources that the costs of higher education have skyrocketed in nominal dollars since the…
Distributing Your OER Materials: A Broadened Approach
The astronomical costs of textbooks are a significant barrier to student success, and Open Educational Resources are a welcome solution…
Safety Trade is Getting Dangerous
The Russell 2000 small-cap index is up nearly 11% so far this year, while the venerable old S&P 500 is…
Why AI Won’t Take Over the World (yet)
As it currently stands, research into artificial intelligence (AI) is focused on getting computers to think like people. We’ve made…
Factor Investing vs. Themes: False Dichotomy?
In most treatments of stock selection, thematic investing (in the selection of individual securities) is often contrasted with factor investing. The…